Sådan optimeres enkeltsider for søgemaskiner
Når Google og andre søgemaskiner indekserer websites, udfører de ikke JavaScript. Dette ser ud til at sætte sider med enkelt sider - hvoraf mange er afhængige af JavaScript - med en enorm ulempe i forhold til en traditionel hjemmeside.
Ikke at være på Google, kunne nemt betyde en virksomheds død, og denne skræmmende faldgrube kunne friste de uinformerede til at opgive enkeltwebsider helt.
Enkelt side sites har imidlertid en fordel over traditionelle hjemmesider i søgemaskineoptimering (SEO), fordi Google og andre har anerkendt udfordringen. De har oprettet en mekanisme til enkeltsider, der ikke kun indekserer deres dynamiske sider, men også optimerer deres sider specifikt til crawlere.
I denne artikel vil vi fokusere på Google, men andre store søgemaskiner som Yahoo! og Bing støtter den samme mekanisme.
Hvordan Google gennemgår en enkelt side-side
Når Google indekserer et traditionelt websted, scanner webcrawleren (kaldet Googlebot) først og indekserer indholdet af top-URI'en (f.eks. Www.myhome.com). Når dette er færdigt, følger det så alle linkene på den side og indekserer også disse sider. Det følger derefter linkene på de efterfølgende sider, og så videre. Til sidst indekserer det alt indhold på webstedet og tilhørende domæner.
Når Googlebot forsøger at indeksere et enkelt sidewebsted, er alt det, der ses i HTML'en, en enkelt tom container (normalt et tomt div eller body tag), så der er intet at indeksere og ingen links til at gennemgå, og det indekserer webstedet i overensstemmelse hermed ( i den runde cirkulære "mappe" på gulvet ved siden af skrivebordet).
Hvis det var slutningen af historien, ville det være slutningen på enkeltsider for mange webapplikationer og websteder. Heldigvis har Google og andre søgemaskiner anerkendt betydningen af enkeltsider og leveret værktøjer til at give udviklere mulighed for at give søgeinformation til crawleren, der kan være bedre end traditionelle hjemmesider.
Sådan laver du en enkelt sidewebsted, der kan gennemsøges
Den første nøgle til at gøre vores enkelt side site gennemgribelig er at indse, at vores server kan fortælle, om en forespørgsel foretages af en crawler eller af en person, der bruger en webbrowser og svarer i overensstemmelse hermed. Når vores besøgende er en person, der bruger en webbrowser, skal du svare som normalt, men for en crawler skal du returnere en side optimeret til at vise crawleren præcis, hvad vi vil, i et format, som crawleren let kan læse.
For hjemmesiden på vores websted, hvordan ser en crawleroptimeret side ud? Det er sandsynligvis vores logo eller andet primært billede, vi gerne vil se i søgeresultater, nogle SEO optimeret tekst forklarer, hvad webstedet er eller gør, og en liste over HTML-links til kun de sider, vi vil have Google til at indeksere. Hvad siden ikke har, er nogen CSS styling eller kompleks HTML struktur anvendt til den. Det har heller ikke nogen JavaScript eller links til områder af webstedet, som vi ikke vil have Google til at indeksere (f.eks. Juridiske ansvarsfraskrivelsessider eller andre sider, vi ikke ønsker, at folk skal indtaste via en Google-søgning). Billedet nedenfor viser, hvordan en side kan blive præsenteret for en browser (til venstre) og til webcrawleren (til højre).
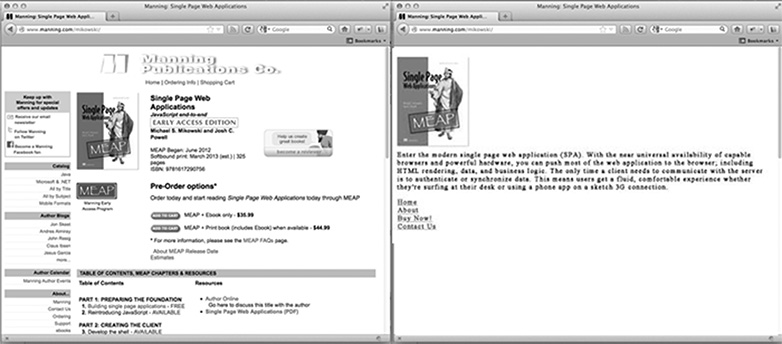
Tilpasning af indhold til crawlere
Normalt linker enkeltsider til forskellige indhold ved hjælp af et hash-bang (#!). Disse links følges ikke på samme måde af mennesker og crawlere.
For eksempel, hvis et link til brugerens side på vores webstedsside ligner /index.htm#!page=user:id,123 , ville crawleren se #! og ved at kigge efter en webside med URI / index.htm ? _escaped_fragment_= page=user: id,123 . At vide, at crawleren vil følge mønsteret og kigge efter denne URI, kan vi programmere serveren til at reagere på denne anmodning med et HTML snapshot af siden, som normalt ville blive fremført af JavaScript i browseren.
Det øjebliksbillede vil blive indekseret af Google, men alle, der klikker på vores fortegnelse i Googles søgeresultater, bliver taget til /index.htm#!page=user:id,123 . JavaScript-siden for den enkelte side vil overtage derfra og gøre siden som forventet.
Dette giver single side site udviklere mulighed for at skræddersy deres hjemmeside specifikt til Google og specifikt til brugere. I stedet for at skrive tekst, der er både læselig og attraktiv for en person og forståelig af en crawler, kan sider optimeres for hver uden at bekymre sig om den anden. Crawlerens sti gennem vores websted kan styres, så vi kan lede personer fra Googles søgeresultater til et bestemt sæt indgangs sider. Dette vil kræve mere arbejde fra ingeniørens side at udvikle sig, men det kan have store udbetalinger med hensyn til søgeresultatposition og kundens opbevaring.
Registrering af Googles webcrawler
På tidspunktet for denne skrivelse annoncerer Googlebot sig som en crawler til serveren ved at stille anmodninger med en bruger-agent streng af Googlebot / 2.1 (+ http://www.googlebot.com / bot.html) . En Node.js-applikation kan tjekke for denne brugeragentstreng i middleware og sende den crawleroptimerede startside tilbage, hvis brugeragentstrengen matcher. Ellers kan vi håndtere anmodningen normalt.
Denne arrangement synes at være kompliceret at teste, da vi ikke ejer en Googlebot. Men Google tilbyder en tjeneste til at gøre dette for offentligt tilgængelige produktionswebsteder som en del af sit webmasterværktøj, men en nemmere måde at teste på er at spoof vores brugeragentstreng. Dette plejede at kræve nogle kommandolinje hackery, men Chrome Developer Tools gør det lige så nemt som at klikke på en knap og markere en boks:
Åbn Chrome Developer Tools ved at klikke på knappen med tre vandrette linjer til højre for Google Toolbar og derefter vælge Tools fra menuen og klikke på Developer Tools.
I nederste højre hjørne af skærmen er et tandhjulsikon: klik på det og se nogle avancerede udviklerindstillinger, som f.eks. Deaktivering af cache og aktivering af logføring af XmlHttpRequests.
På den anden fane, der hedder Overrides, skal du klikke på afkrydsningsfeltet ud for etiketten Brugeragent og vælge et hvilket som helst antal brugeragenter fra rullemenuen fra Chrome, Firefox, IE, iPads og meget mere. Googlebot-agenten er ikke en standardindstilling. For at bruge den skal du vælge Andet og kopiere og indsætte brugeragentstrengen i den angivne indgang.
Nu er denne fane spoofing sig selv som en Googlebot, og når vi åbner nogen URI på vores websted, bør vi se siden for crawler.
Afslutningsvis
Naturligvis vil forskellige applikationer have forskellige behov med hensyn til hvad man skal gøre med webcrawlere, men det er nok ikke nok nok at have en side returneret til Googlebot. Vi skal også beslutte, hvilke sider vi vil eksponere og give måder til vores applikation at kortlægge _escaped_fragment_ = key = værdien URI til det indhold, vi vil vise dem.
Du ønsker måske at få lyst til og knytte serverens respons ind i front-end-rammerne, men jeg bruger normalt den enklere tilgang her og opretter brugerdefinerede sider til crawleren og sætter dem i en separat routerfil til crawlere.
Der er også mange mere legitime crawlere derude, så når vi har justeret vores server til Google-crawleren, kan vi udvide dem til også at omfatte dem.
Bygger du enkeltwebsider? Hvordan udfører enkeltwebsider på søgemaskiner? Lad os vide dine tanker i kommentarerne.
Fremhævet billede / miniaturebillede, søge billede via Shutterstock.